学習モデル
次週より、システム変更に着手予定です。
めざましじゃんけん関係で、各種技術を深めております。
各種技術情報の詳細は、随時公開を進めます。
良い学習モデルが仕上がりました。現時点では、ベストかなと感じてます。
(8月15日より学習モデルは新バージョンで稼働しており、めざましじゃんけん後の結果公開までを1分30秒ほど短縮しております、限りなくゼロに近づけます。)
今までは、7時58分のジャンケン結果を8時01分31秒にホームページ更新、Twitter投稿から、新エンジンで8時00分00秒にホームページ更新、Twitter投稿に時間短縮。画像検出方法変更のみで1分半ほどの時間短縮を実現しています。
あと1分詰めれば、ジャンケン終了とほぼ同時に結果公開が可能となります。
以下、WindowsマシンでGPUなし、OpenCV dnnで速度測定。
import cv2 as cv net = cv.dnn.readNetFromDarknet(CFG, MODEL) net.setPreferableBackend(cv.dnn.DNN_BACKEND_DEFAULT) net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
めざましじゃんけんシステムのテスト環境(228枚の画像)
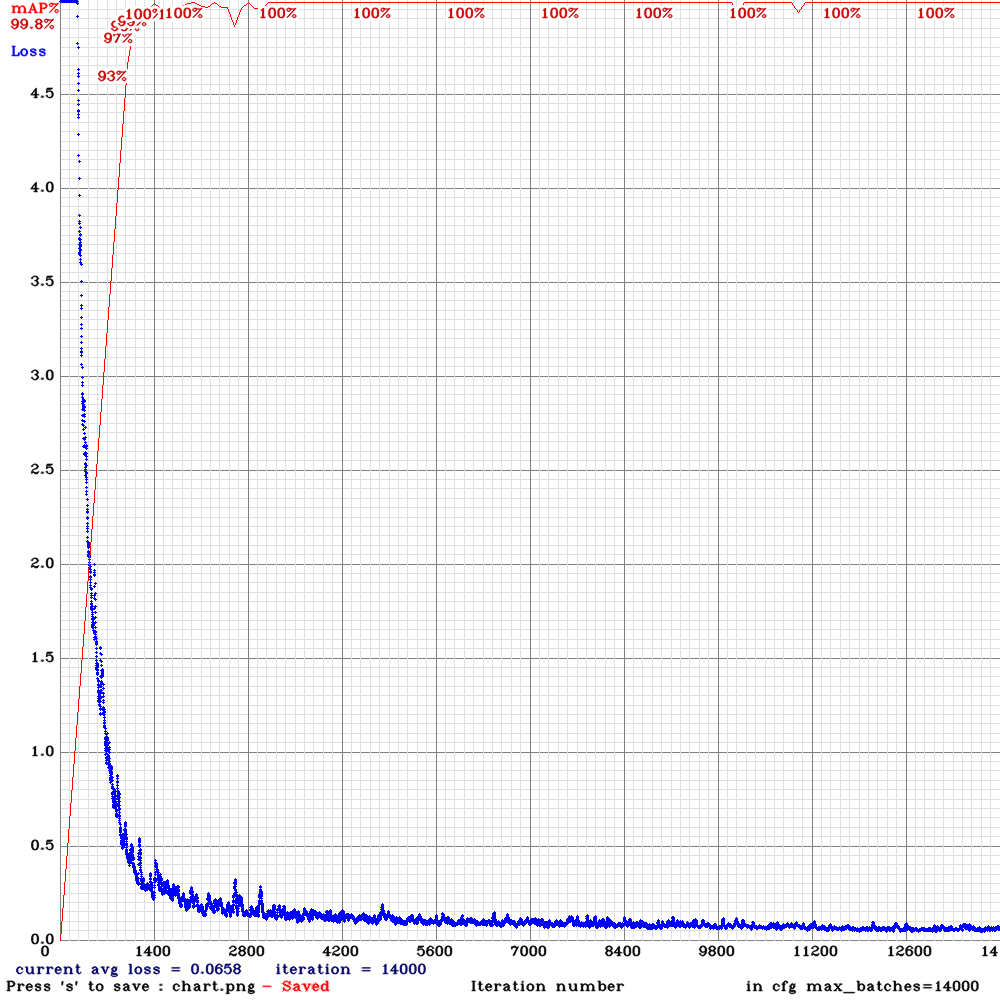
- 第二世代(現行):109秒、平均99%以上の認識率
- 開発バージョン1:16秒、平均65%以上の認識率
- 開発バージョン2(次期本番向け):15秒、平均99%以上の認識率
第二世代(現行)の学習曲線
GPUの容量不足により多くの時間を要しました。検出速度よりも正確さを重視し、システム稼働後に本番システムに導入しました。めざましテレビ終了後よりめざましテレビが始まる時間を利用し、2日間かけて学習させました。
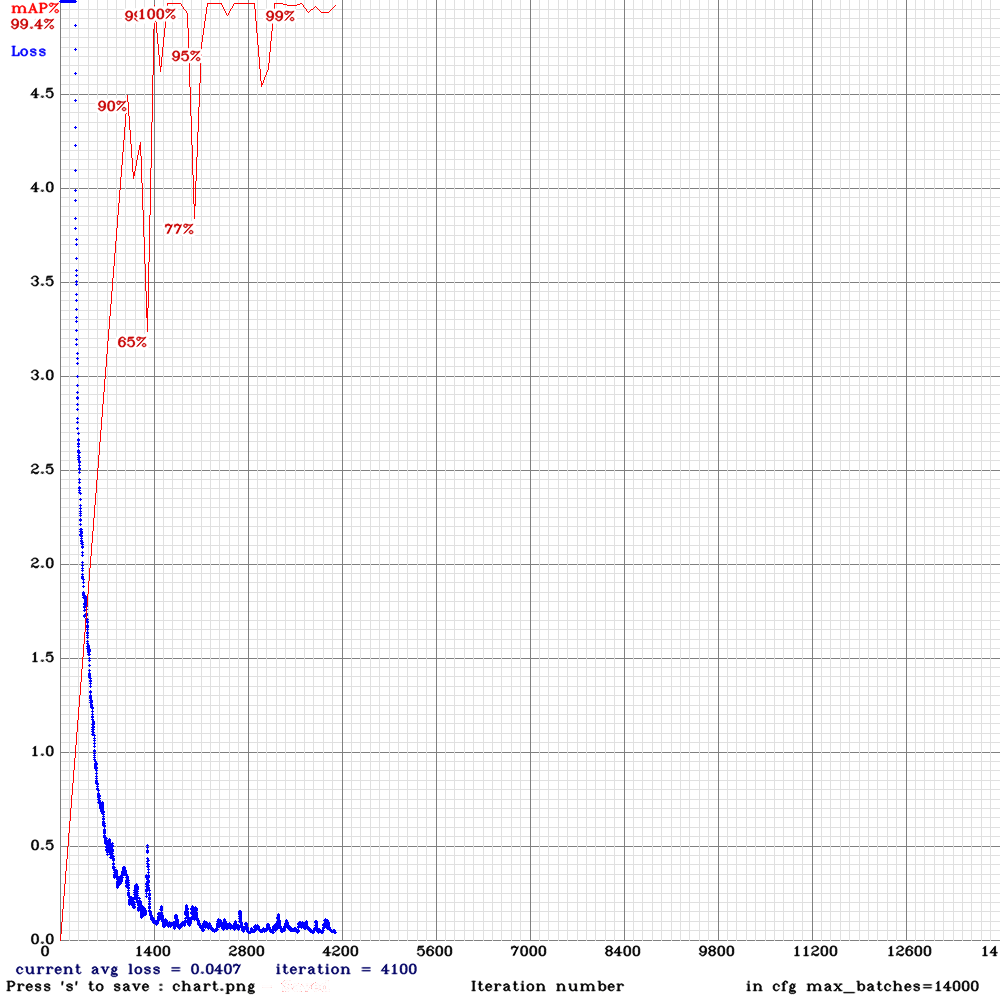
開発バージョン1の学習曲線
速度向上を目的に、追加開発を継続しました。速度は向上しましたが、認識率が一気に下がりました。
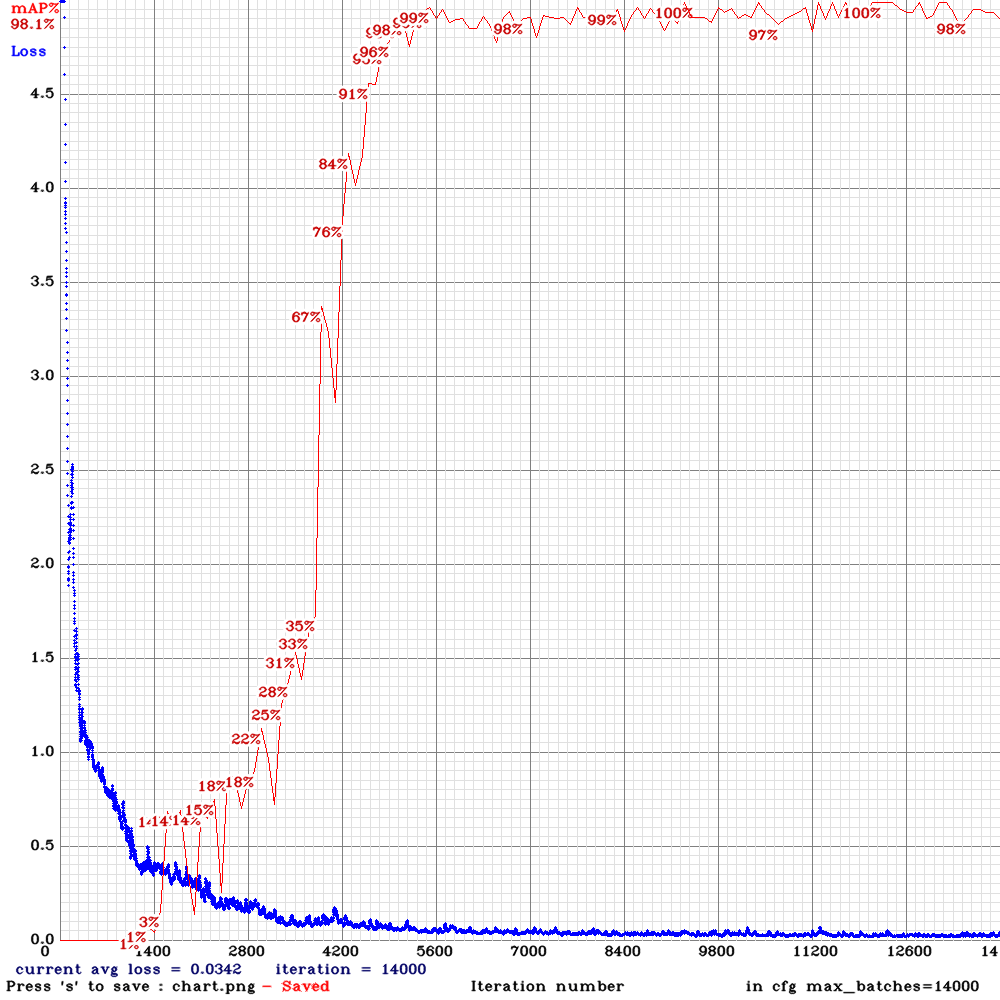
開発バージョン2(次期本番向け)
速度、認識率ともに問題なしです。
この学習モデルを本番投入します。
また、このモデルを用いて、Raspberry Piでのオンザフライ(放送中)での結果解析を進めます。現在のメインマシンWindowsからRaspberry Piで動作させた際の速度比較も気になります。