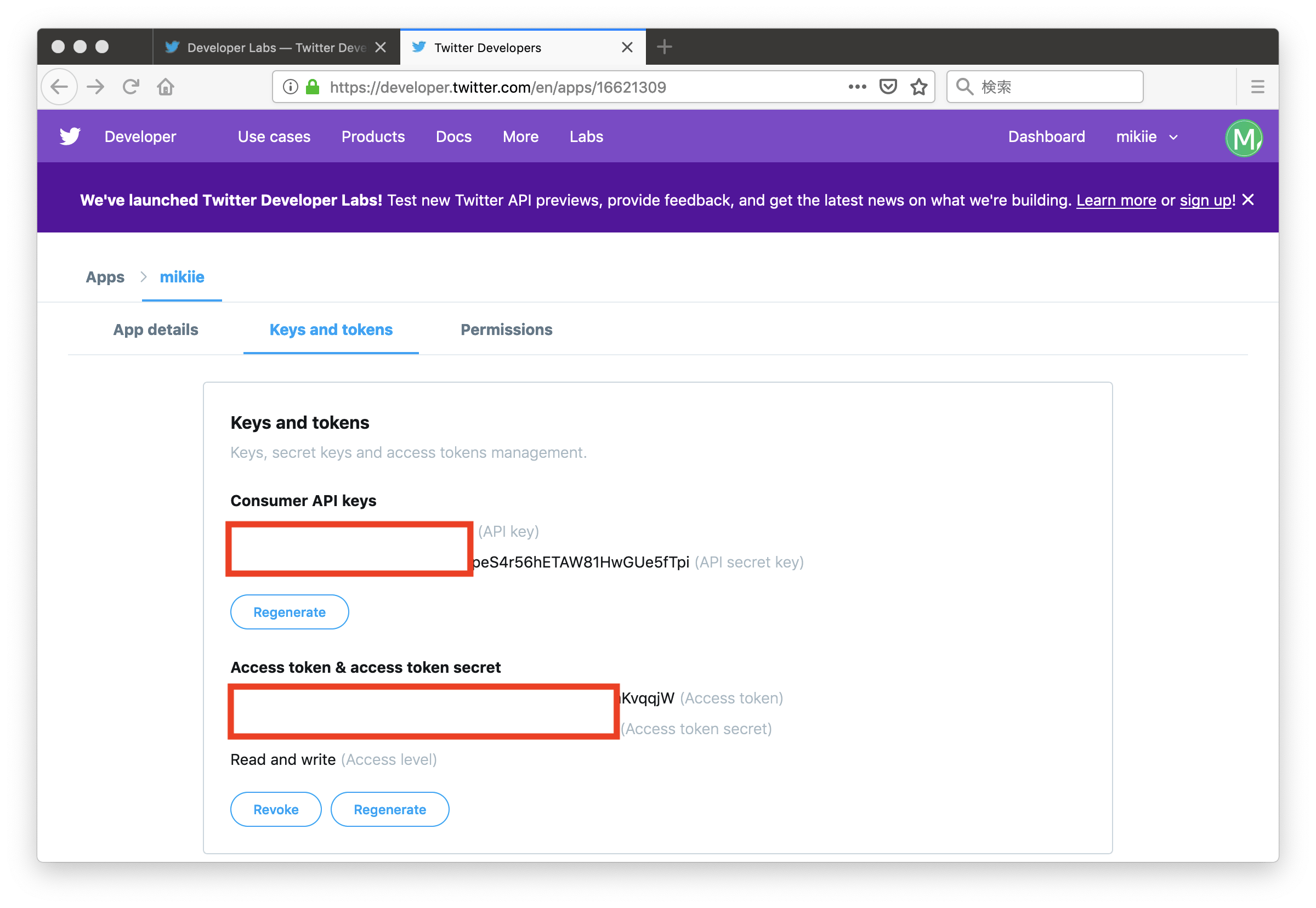
Exception in main training loop: out of memory to allocate 134217728 bytes (total 816308736 bytes)
Traceback (most recent call last):
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\trainer.py", line 315, in run
update()
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\updaters\standard_updater.py", line 165, in update
self.update_core()
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\updaters\standard_updater.py", line 177, in update_core
optimizer.update(loss_func, *in_arrays)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\optimizer.py", line 685, in update
loss.backward(loss_scale=self._loss_scale)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\variable.py", line 981, in backward
self._backward_main(retain_grad, loss_scale)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\variable.py", line 1061, in _backward_main
func, target_input_indexes, out_grad, in_grad)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\_backprop_utils.py", line 109, in backprop_step
target_input_indexes, grad_outputs)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\functions\activation\relu.py", line 75, in backward
return ReLUGrad2(y).apply((gy,))
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\function_node.py", line 263, in apply
outputs = self.forward(in_data)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\function_node.py", line 369, in forward
return self.forward_gpu(inputs)
File "C:\Users\user\Anaconda3\envs\Own-Project\lib\site-packages\chainer\functions\activation\relu.py", line 103, in forward_gpu
gx = _relu_grad2_kernel(self.b, inputs[0])
File "cupy\core\_kernel.pyx", line 547, in cupy.core._kernel.ElementwiseKernel.__call__
File "cupy\core\_kernel.pyx", line 369, in cupy.core._kernel._get_out_args_with_params
File "cupy\core\core.pyx", line 134, in cupy.core.core.ndarray.__init__
File "cupy\cuda\memory.pyx", line 518, in cupy.cuda.memory.alloc
File "cupy\cuda\memory.pyx", line 1085, in cupy.cuda.memory.MemoryPool.malloc
File "cupy\cuda\memory.pyx", line 1106, in cupy.cuda.memory.MemoryPool.malloc
File "cupy\cuda\memory.pyx", line 934, in cupy.cuda.memory.SingleDeviceMemoryPool.malloc
File "cupy\cuda\memory.pyx", line 949, in cupy.cuda.memory.SingleDeviceMemoryPool._malloc
File "cupy\cuda\memory.pyx", line 697, in cupy.cuda.memory._try_malloc
Will finalize trainer extensions and updater before reraising the exception.
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
<ipython-input-24-041e2033e90a> in <module>
----> 1 trainer.run()
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\trainer.py in run(self, show_loop_exception_msg)
327 f.write('Will finalize trainer extensions and updater before '
328 'reraising the exception.\n')
--> 329 six.reraise(*sys.exc_info())
330 finally:
331 for _, entry in extensions:
~\Anaconda3\envs\Own-Project\lib\site-packages\six.py in reraise(tp, value, tb)
691 if value.__traceback__ is not tb:
692 raise value.with_traceback(tb)
--> 693 raise value
694 finally:
695 value = None
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\trainer.py in run(self, show_loop_exception_msg)
313 self.observation = {}
314 with reporter.scope(self.observation):
--> 315 update()
316 for name, entry in extensions:
317 if entry.trigger(self):
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\updaters\standard_updater.py in update(self)
163
164 """
--> 165 self.update_core()
166 self.iteration += 1
167
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\training\updaters\standard_updater.py in update_core(self)
175
176 if isinstance(in_arrays, tuple):
--> 177 optimizer.update(loss_func, *in_arrays)
178 elif isinstance(in_arrays, dict):
179 optimizer.update(loss_func, **in_arrays)
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\optimizer.py in update(self, lossfun, *args, **kwds)
683 else:
684 self.target.zerograds()
--> 685 loss.backward(loss_scale=self._loss_scale)
686 del loss
687
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\variable.py in backward(self, retain_grad, enable_double_backprop, loss_scale)
979 """
980 with chainer.using_config('enable_backprop', enable_double_backprop):
--> 981 self._backward_main(retain_grad, loss_scale)
982
983 def _backward_main(self, retain_grad, loss_scale):
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\variable.py in _backward_main(self, retain_grad, loss_scale)
1059
1060 _backprop_utils.backprop_step(
-> 1061 func, target_input_indexes, out_grad, in_grad)
1062
1063 for hook in hooks:
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\_backprop_utils.py in backprop_step(func, target_input_indexes, grad_outputs, grad_inputs)
107 else: # otherwise, backward should be overridden
108 gxs = func.backward(
--> 109 target_input_indexes, grad_outputs)
110
111 if is_debug:
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\functions\activation\relu.py in backward(self, indexes, grad_outputs)
73 return ReLUGradCudnn(x, y).apply((gy,))
74 # Generic implementation
---> 75 return ReLUGrad2(y).apply((gy,))
76
77
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\function_node.py in apply(self, inputs)
261 outputs = static_forward_optimizations(self, in_data)
262 else:
--> 263 outputs = self.forward(in_data)
264
265 # Check for output array types
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\function_node.py in forward(self, inputs)
367 assert len(inputs) > 0
368 if isinstance(inputs[0], cuda.ndarray):
--> 369 return self.forward_gpu(inputs)
370 return self.forward_cpu(inputs)
371
~\Anaconda3\envs\Own-Project\lib\site-packages\chainer\functions\activation\relu.py in forward_gpu(self, inputs)
101
102 def forward_gpu(self, inputs):
--> 103 gx = _relu_grad2_kernel(self.b, inputs[0])
104 return gx,
105
cupy\core\_kernel.pyx in cupy.core._kernel.ElementwiseKernel.__call__()
cupy\core\_kernel.pyx in cupy.core._kernel._get_out_args_with_params()
cupy\core\core.pyx in cupy.core.core.ndarray.__init__()
cupy\cuda\memory.pyx in cupy.cuda.memory.alloc()
cupy\cuda\memory.pyx in cupy.cuda.memory.MemoryPool.malloc()
cupy\cuda\memory.pyx in cupy.cuda.memory.MemoryPool.malloc()
cupy\cuda\memory.pyx in cupy.cuda.memory.SingleDeviceMemoryPool.malloc()
cupy\cuda\memory.pyx in cupy.cuda.memory.SingleDeviceMemoryPool._malloc()
cupy\cuda\memory.pyx in cupy.cuda.memory._try_malloc()
OutOfMemoryError: out of memory to allocate 134217728 bytes (total 816308736 bytes)





 Choki(チョキ)
Choki(チョキ)  Pa(パー)
Pa(パー)