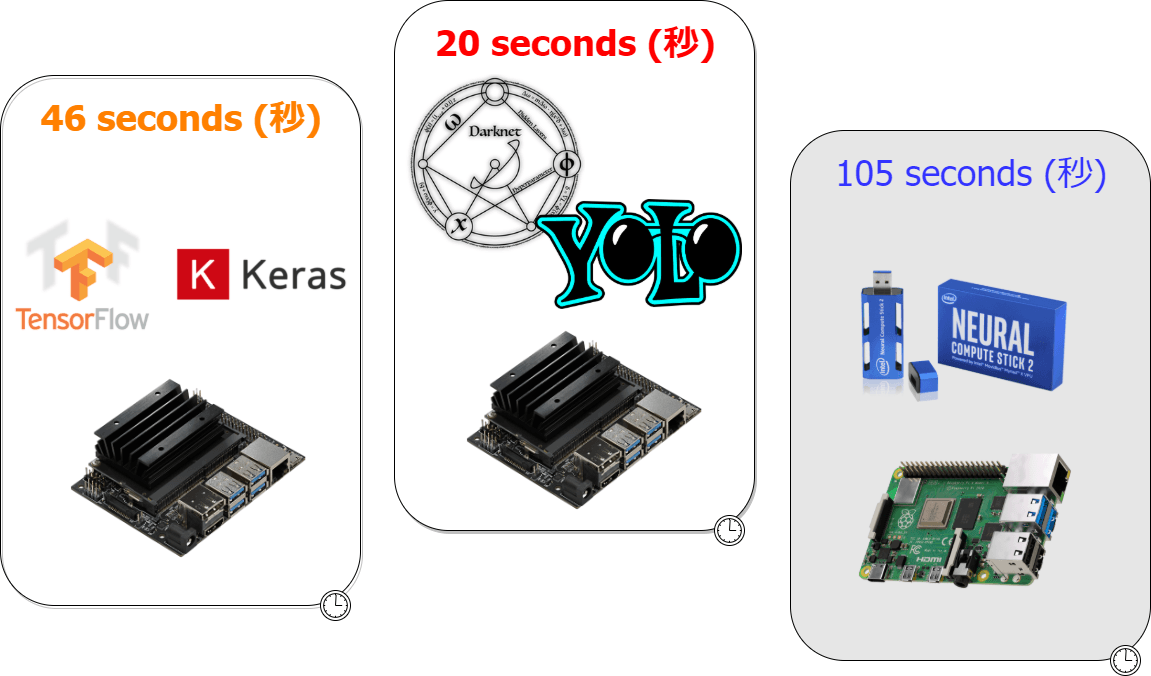
Yolo3、Tiny-Yolo3での独自学習モデルをPythonに実装
画像検出に向けて、AlexeyAB Darknetを用いて、YOLO3、Tiny-YOLO3で作成した、独自学習モデルをPythonで実装します。
前提条件
YOLO2 Tiny-YOLO2 YOLO3 Tiny-YOLO3 をPythonで実装
学習済みモデル(weightsファイル)とコンフィグファイル(cfgファイル)
「darknet\build\darknet\x64\cfg\obj.data」ファイルのbackupに指定したフォルダに、学習モデル(weightsファイル)が出力されます。
classes = 7
train = train.txt
valid = test.txt
names = cfg/obj.names
backup = backup/
独自学習に用いたコンフィグファイルは、「darknet\build\darknet\x64\cfg\」フォルダ内で作成していると思いますので、独自学習時に用いたcfgファイルとなります。
これらのファイルを、画像検出を実施するRaspberry PiやサーバーのPythonファイルが読み込み可能な場所にコピーします。
Python3での実装
- net = cv.dnn.readNetFromDarknet(CFG, MODEL)
- CFG:学習モデル(weightsファイル)
- MODEL:独自学習時に用いたcfgファイル
- net.setPreferableTarget
- net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
Raspberry PiやWindowsなどで動作させる際のTarget指定。
現時点では、OpenCVのYOLO向けDNNでは、GPUはサポートされておりません。 - net.setPreferableTarget(cv.dnn.DNN_TARGET_MYRIAD)
Intel Movidius Neural Compute Stick 2 (NCS2)を利用する際は、TargetにNCS2を指定することが出来ます。Raspberry Pi 3B +で動作確認済みとなります。
参考記事:Movidius Neural Compute Stick 2、OpenVINO™ toolkit for Raspbian* OS導入
Python3 ソースコード
サンプルスクリプトを掲載しておきます。
#!/usr/bin/env python
# coding: utf-8
target_model = "yolov3-tiny-janken_final.weights"
target_config = "yolov3-tiny-janken.cfg"
import cv2 as cv
import numpy as np
MODEL = "./janken_cfg/" + target_model
CFG = "./janken_cfg/" + target_config
SCALE = 0.00392 ##1/255
INP_SHAPE = (416, 416) #input size
MEAN = 0
RGB = True
# Load a network
net = cv.dnn.readNetFromDarknet(CFG, MODEL)
net.setPreferableBackend(cv.dnn.DNN_BACKEND_DEFAULT)
##net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
net.setPreferableTarget(cv.dnn.DNN_TARGET_MYRIAD)
confThreshold = 0.8 # Confidence threshold
nmsThreshold = 0.8 # Non-maximum supression threshold
class_names = ['active', 'goo', 'choki', 'pa', 'won', 'lose', 'draw']
def getOutputsNames(net):
layersNames = net.getLayerNames()
return [layersNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
def postprocess(frame, outs):
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
def drawPred(classId, conf, left, top, right, bottom):
left = int(left)
top = int(top)
right = int(right)
bottom = int(bottom)
# Draw a bounding box.
cv.rectangle(frame, (left, top), (right, bottom), (0, 255, 0))
label = class_names[classId] + '_%.2f' % conf
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
top = max(top, labelSize[1])
cv.rectangle(frame, (left, top - labelSize[1]), (left + labelSize[0], top + baseLine), (255, 255, 255), cv.FILLED)
cv.putText(frame, label, (left, top), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
layerNames = net.getLayerNames()
lastLayerId = net.getLayerId(layerNames[-1])
lastLayer = net.getLayer(lastLayerId)
classIds = []
confidences = []
boxes = []
if lastLayer.type == 'Region':
classIds = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
classId = np.argmax(scores)
confidence = scores[classId]
if confidence > confThreshold:
center_x = int(detection[0] * frameWidth)
center_y = int(detection[1] * frameHeight)
width = int(detection[2] * frameWidth)
height = int(detection[3] * frameHeight)
left = center_x - width / 2
top = center_y - height / 2
classIds.append(classId)
confidences.append(float(confidence))
boxes.append([left, top, width, height])
else:
print('Unknown output layer type: ' + lastLayer.type)
exit()
indices = cv.dnn.NMSBoxes(boxes, confidences, confThreshold, nmsThreshold)
for i in indices:
i = i[0]
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
drawPred(classIds[i], confidences[i], left, top, left + width, top + height)
c = cv.VideoCapture(0)
c.set(cv.CAP_PROP_FRAME_WIDTH, 640) # カメラ画像の横幅を1280に設定
c.set(cv.CAP_PROP_FRAME_HEIGHT, 480) # カメラ画像の縦幅を720に設定
c.read()
r, frame = c.read()
frameHeight = frame.shape[0]
frameWidth = frame.shape[1]
# Create a 4D blob from a frame.
inpWidth = INP_SHAPE[0]
inpHeight = INP_SHAPE[1]
blob = cv.dnn.blobFromImage(frame, SCALE, (inpWidth, inpHeight), MEAN, RGB, crop=False)
# Run a model
net.setInput(blob)
outs = net.forward(getOutputsNames(net))
##print(outs)
postprocess(frame, outs)
# Put efficiency information.
t, _ = net.getPerfProfile()
label = 'Inference time: %.2f ms' % (t * 1000.0 / cv.getTickFrequency())
cv.putText(frame, label, (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0))
#対象ファイルコピー保存
target_filepath = './result.jpg'
cv.imwrite(target_filepath, frame)