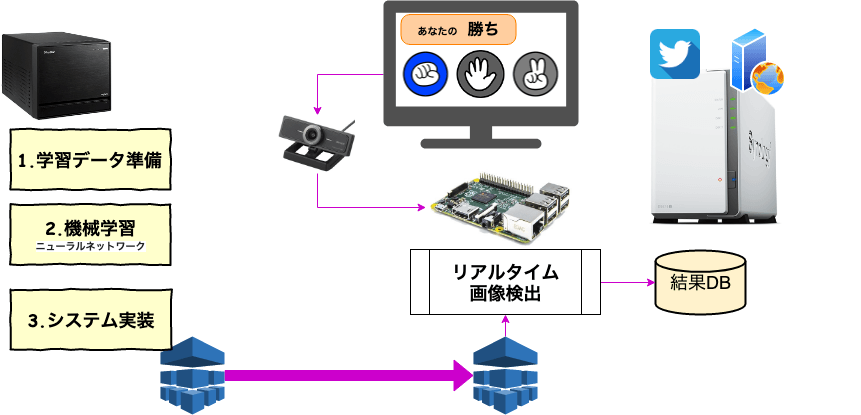
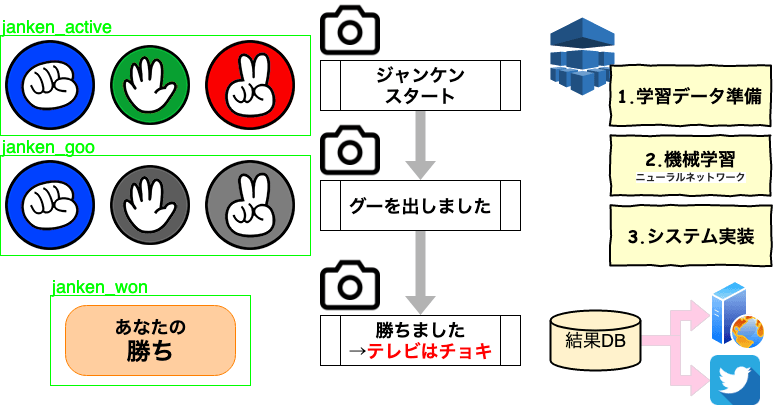
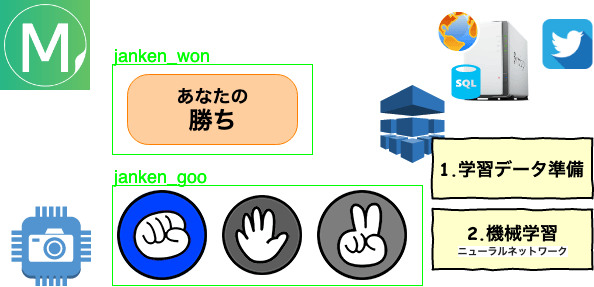
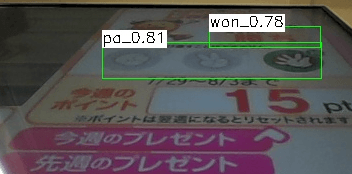
Darknet/YOLOの独自学習に向けた画像準備
独自/オリジナルの1クラスを勉強させるのに多くの画像データが必要となります。WEBの記事では、1クラス数千枚と記載されておりました。このサイトで公開しているめざましじゃんけん画像検出も精度向上で画像追加を適時行っておりますが、サービス提供開始時点でトータル5000枚(4クラス合計)で開始しております。
インターネットからキーワードで画像データを探してくるツールや、機械学習向けのデータセットを公開しているサイトなどもあるようです。
機械学習向けデータセット公開サイト:ImageNet
80,000を超える対象のデータセットが準備されているようです。
Raspberry Piに接続したUSBカメラで機械学習向けデータセット準備
Raspberry PiにUSB接続のWEBカメラ導入
当初、扱いが楽なfswebcamを利用して実施しようとしましたが、結局は画像検出でも多用するOpenCVを利用した画像準備を実施しました。
めざましじゃんけんでは、結果表示時間が短いこともあり、短時間で多くの画像取得をする必要がありました。fswebcamはコマンドで閉じた画像取得ができるのがメリットとなりますが、カメラの準備や利用終了などが一連の流れとしてコマンド化されており、画像の連続取得には適しておりませんでした。Sleepなしで連続画像取得をした際に、Raspberry Piでは1画像/3−8秒必要となっておりました。このインターバルが不揃いであった点も利用に至らなかった要因です。
fswebcamインストールと機械学習向けデータセット
@raspberrypi: $ sudo apt-get install fswebcam
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
libboost-system1.62.0 libboost-thread1.62.0 libreoffice-gtk2
Use 'sudo apt autoremove' to remove them.
The following NEW packages will be installed:
fswebcam
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
Need to get 43.5 kB of archives.
After this operation, 116 kB of additional disk space will be used.
Get:1 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf fswebcam armhf 20140113-2 [43.5 kB]
Fetched 43.5 kB in 1s (39.0 kB/s)
perl: warning: Setting locale failed.
perl: warning: Please check that your locale settings:
LANGUAGE = (unset),
LC_ALL = (unset),
LC_CTYPE = "UTF-8",
LANG = "ja_JP.UTF-8"
are supported and installed on your system.
perl: warning: Falling back to a fallback locale ("ja_JP.UTF-8").
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: LC_ALL??????????????????: ??????????????????????
Selecting previously unselected package fswebcam.
(Reading database ... 151227 files and directories currently installed.)
Preparing to unpack .../fswebcam_20140113-2_armhf.deb ...
Unpacking fswebcam (20140113-2) ...
Setting up fswebcam (20140113-2) ...
Processing triggers for man-db (2.8.5-2) ...画像取得時のコマンド
以下のコマンドで、画像保存を行いました。
/usr/bin/fswebcam -r 640x480 -F100 /mnt/synology/capture/`date "+%Y%m%d_%H%M%S"`.jpg
参考にさせて頂いたサイト
OpenCVインストールと機械学習向けデータセット
今後、Raspberry Pi上でのOpenCVインストール方法を記事にしますが、簡単な画像処理には、以下コマンドで入るOpenCVで特に問題は有りませんでした。
apt-get install python-opencv
OpenCVの利用方法
- OpenCVをインポート
import cv2 - カメラデバイスを取得
c = cv2.VideoCapture(0) - カメラ起動待ち
Sleepを少し入れるか、c.read()を画像取得なしで実行します
※ カメラ依存と思いますが、最初の画像が暗くなる傾向があります。 - readで画像をキャプチャ、imgにRGBのデータが入ってくる
r, img = c.read() - ファルへ保存
cv2.imwrite('photo.jpg', img)
参考にさせて頂いたサイト
[Raspberry Pi]USBカメラをつなぎ、PythonのOpenCVで写真を撮る

python-opencvインストールログ
@raspberrypi:$ sudo apt-get install python-opencv [sudo] パスワード: パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 以下のパッケージが自動でインストールされましたが、もう必要とされていません: libboost-system1.62.0 libboost-thread1.62.0 libreoffice-gtk2 これを削除するには 'sudo apt autoremove' を利用してください。 以下の追加パッケージがインストールされます: gdal-data gfortran gfortran-8 libaec0 libarmadillo9 libarpack2 libcaf-openmpi-3 libcharls2 libcoarrays-dev libcoarrays-openmpi-dev libdap25 libdapclient6v5 libdapserver7v5 libepsilon1 libevent-core-2.1-6 libevent-pthreads-2.1-6 libfreexl1 libfyba0 libgdal20 libgdcm2.8 libgeos-3.7.1 libgeos-c1v5 libgeotiff2 libgfortran-8-dev libgl2ps1.4 libhdf4-0-alt libhdf5-103 libhdf5-openmpi-103 libhwloc-dev libhwloc-plugins libhwloc5 libibverbs-dev libkmlbase1 libkmlconvenience1 libkmldom1 libkmlengine1 libkmlregionator1 libkmlxsd1 liblept5 libmariadb3 libminizip1 libnetcdf-c++4 libnetcdf13 libnl-3-dev libnl-route-3-dev libodbc1 libogdi3.2 libopencv-calib3d3.2 libopencv-contrib3.2 libopencv-core3.2 libopencv-features2d3.2 libopencv-flann3.2 libopencv-highgui3.2 libopencv-imgcodecs3.2 libopencv-imgproc3.2 libopencv-ml3.2 libopencv-objdetect3.2 libopencv-photo3.2 libopencv-shape3.2 libopencv-stitching3.2 libopencv-superres3.2 libopencv-video3.2 libopencv-videoio3.2 libopencv-videostab3.2 libopencv-viz3.2 libopenmpi-dev libopenmpi3 libpmix2 libproj13 libqhull7 libsocket++1 libspatialite7 libsuperlu5 libsz2 libtbb2 libtesseract4 liburiparser1 libvtk6.3 libxerces-c3.2 mariadb-common mysql-common ocl-icd-libopencl1 odbcinst odbcinst1debian2 openmpi-bin openmpi-common proj-bin proj-data 提案パッケージ: gfortran-doc gfortran-8-doc libgfortran5-dbg geotiff-bin gdal-bin libgeotiff-epsg libhdf4-doc libhdf4-alt-dev hdf4-tools libhwloc-contrib-plugins libmyodbc odbc-postgresql tdsodbc unixodbc-bin ogdi-bin openmpi-doc mpi-default-bin vtk6-doc vtk6-examples opencl-icd 以下のパッケージが新たにインストールされます: gdal-data gfortran gfortran-8 libaec0 libarmadillo9 libarpack2 libcaf-openmpi-3 libcharls2 libcoarrays-dev libcoarrays-openmpi-dev libdap25 libdapclient6v5 libdapserver7v5 libepsilon1 libevent-core-2.1-6 libevent-pthreads-2.1-6 libfreexl1 libfyba0 libgdal20 libgdcm2.8 libgeos-3.7.1 libgeos-c1v5 libgeotiff2 libgfortran-8-dev libgl2ps1.4 libhdf4-0-alt libhdf5-103 libhdf5-openmpi-103 libhwloc-dev libhwloc-plugins libhwloc5 libibverbs-dev libkmlbase1 libkmlconvenience1 libkmldom1 libkmlengine1 libkmlregionator1 libkmlxsd1 liblept5 libmariadb3 libminizip1 libnetcdf-c++4 libnetcdf13 libnl-3-dev libnl-route-3-dev libodbc1 libogdi3.2 libopencv-calib3d3.2 libopencv-contrib3.2 libopencv-core3.2 libopencv-features2d3.2 libopencv-flann3.2 libopencv-highgui3.2 libopencv-imgcodecs3.2 libopencv-imgproc3.2 libopencv-ml3.2 libopencv-objdetect3.2 libopencv-photo3.2 libopencv-shape3.2 libopencv-stitching3.2 libopencv-superres3.2 libopencv-video3.2 libopencv-videoio3.2 libopencv-videostab3.2 libopencv-viz3.2 libopenmpi-dev libopenmpi3 libpmix2 libproj13 libqhull7 libsocket++1 libspatialite7 libsuperlu5 libsz2 libtbb2 libtesseract4 liburiparser1 libvtk6.3 libxerces-c3.2 mariadb-common mysql-common ocl-icd-libopencl1 odbcinst odbcinst1debian2 openmpi-bin openmpi-common proj-bin proj-data python-opencv アップグレード: 0 個、新規インストール: 89 個、削除: 0 個、保留: 0 個。 69.6 MB のアーカイブを取得する必要があります。 この操作後に追加で 280 MB のディスク容量が消費されます。 続行しますか? [Y/n] y 取得:1 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf gdal-data all 2.4.0+dfsg-1 [744 kB] 取得:2 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgfortran-8-dev armhf 8.3.0-6+rpi1 [249 kB] 取得:4 http://raspbian.raspberrypi.org/raspbian buster/main armhf gfortran armhf 4:8.3.0-1+rpi2 [1,428 B] 取得:8 http://ftp.tsukuba.wide.ad.jp/Linux/raspbian/raspbian buster/main armhf libarmadillo9 armhf 1:9.200.7+dfsg-1 [87.0 kB] 取得:3 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf gfortran-8 armhf 8.3.0-6+rpi1 [7,202 kB] 取得:5 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libaec0 armhf 1.0.2-1 [21.3 kB] 取得:6 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libarpack2 armhf 3.7.0-2 [83.1 kB] 取得:7 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libsuperlu5 armhf 5.2.1+dfsg1-4 [126 kB] 取得:11 http://ftp.tsukuba.wide.ad.jp/Linux/raspbian/raspbian buster/main armhf libhwloc5 armhf 1.11.12-3+rpi1 [86.3 kB] 取得:9 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libevent-core-2.1-6 armhf 2.1.8-stable-4 [117 kB] 取得:10 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libevent-pthreads-2.1-6 armhf 2.1.8-stable-4 [47.6 kB] 得:12 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf ocl-icd-libopencl1 armhf 2.2.12-2 [35.7 kB] 取得:13 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libhwloc-plugins armhf 1.11.12-3+rpi1 [16.0 kB] 取得:14 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libpmix2 armhf 3.1.2-3 [423 kB] 取得:15 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopenmpi3 armhf 3.1.3-11+rpi1 [1,813 kB] 取得:30 http://ftp.tsukuba.wide.ad.jp/Linux/raspbian/raspbian buster/main armhf proj-data all 5.2.0-1 [6,986 kB] 取得:16 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libcaf-openmpi-3 armhf 2.4.0-2 [31.3 kB] 取得:17 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libcharls2 armhf 2.0.0+dfsg-1 [52.0 kB] 取得:18 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libcoarrays-dev armhf 2.4.0-2 [29.1 kB] 取得:19 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf openmpi-common all 3.1.3-11+rpi1 [164 kB] 取得:20 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf openmpi-bin armhf 3.1.3-11+rpi1 [197 kB] 取得:21 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libcoarrays-openmpi-dev armhf 2.4.0-2 [29.2 kB] 取得:22 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libdap25 armhf 3.20.3-1 [470 kB] 取得:23 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libdapclient6v5 armhf 3.20.3-1 [185 kB] 取得:24 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libdapserver7v5 armhf 3.20.3-1 [127 kB] 取得:25 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libepsilon1 armhf 0.9.2+dfsg-4 [36.4 kB] 取得:26 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libfreexl1 armhf 1.0.5-3 [31.8 kB] 取得:27 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libfyba0 armhf 4.1.1-6 [97.8 kB] 取得:28 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgeos-3.7.1 armhf 3.7.1-1 [637 kB] 取得:29 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgeos-c1v5 armhf 3.7.1-1 [290 kB] 取得:31 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libproj13 armhf 5.2.0-1 [185 kB] 取得:32 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgeotiff2 armhf 1.4.3-1 [63.8 kB] 取得:33 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libhdf4-0-alt armhf 4.2.13-4+b1 [235 kB] 取得:34 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libsz2 armhf 1.0.2-1 [6,640 B] 取得:35 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libhdf5-103 armhf 1.10.4+repack-10 [1,259 kB] 取得:36 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libminizip1 armhf 1.1-8 [18.3 kB] 取得:37 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf liburiparser1 armhf 0.9.1-1 [39.4 kB] 取得:38 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libkmlbase1 armhf 1.3.0-7 [42.1 kB] 取得:39 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libkmldom1 armhf 1.3.0-7 [144 kB] 取得:40 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libkmlengine1 armhf 1.3.0-7 [67.4 kB] 取得:41 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libkmlconvenience1 armhf 1.3.0-7 [44.4 kB] 取得:42 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libkmlregionator1 armhf 1.3.0-7 [22.2 kB] 取得:43 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libkmlxsd1 armhf 1.3.0-7 [28.7 kB] 取得:44 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf mysql-common all 5.8+1.0.5 [7,324 B] 取得:45 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf mariadb-common all 1:10.3.15-1 [31.3 kB] :46 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libmariadb3 armhf 1:10.3.15-1 [167 kB] 取得:47 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libnetcdf13 armhf 1:4.6.2-1+b1 [352 kB] 取得:48 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libodbc1 armhf 2.3.6-0.1 [186 kB] 取得:49 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libogdi3.2 armhf 3.2.1+ds-4 [194 kB] 取得:50 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libqhull7 armhf 2015.2-4 [175 kB] 取得:51 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libspatialite7 armhf 4.3.0a-5+b2 [1,231 kB] 取得:52 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libxerces-c3.2 armhf 3.2.2+debian-1+b1 [707 kB] 取得:53 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf odbcinst armhf 2.3.6-0.1 [47.6 kB] 取得:54 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf odbcinst1debian2 armhf 2.3.6-0.1 [70.8 kB] 取得:55 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgdal20 armhf 2.4.0+dfsg-1+b2 [5,065 kB] 取得:56 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libsocket++1 armhf 1.12.13-10 [35.2 kB] 取得:57 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgdcm2.8 armhf 2.8.8-9 [1,596 kB] 取得:58 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libgl2ps1.4 armhf 1.4.0+dfsg1-2 [34.2 kB] 取得:59 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libhdf5-openmpi-103 armhf 1.10.4+repack-10 [1,306 kB] 取得:60 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libhwloc-dev armhf 1.11.12-3+rpi1 [142 kB] 取得:61 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libnl-3-dev armhf 3.4.0-1 [92.4 kB] 取得:62 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libnl-route-3-dev armhf 3.4.0-1 [145 kB] 取得:63 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libibverbs-dev armhf 22.1-1 [149 kB] 取得:64 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf liblept5 armhf 1.76.0-1 [804 kB] 取得:65 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libnetcdf-c++4 armhf 4.2-11 [28.3 kB] 取得:66 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libtbb2 armhf 2018~U6-4 [110 kB] 取得:67 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-core3.2 armhf 3.2.0+dfsg-6 [602 kB] 取得:68 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-flann3.2 armhf 3.2.0+dfsg-6 [85.5 kB] 取得:69 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-imgproc3.2 armhf 3.2.0+dfsg-6 [682 kB] 取得:70 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-imgcodecs3.2 armhf 3.2.0+dfsg-6 [80.8 kB] 取得:71 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-videoio3.2 armhf 3.2.0+dfsg-6 [82.0 kB] 取得:72 http://ftp.tsukuba.wide.ad.jp/Linux/raspbian/raspbian buster/main armhf libopencv-highgui3.2 armhf 3.2.0+dfsg-6 [30.1 kB] 取得:73 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-ml3.2 armhf 3.2.0+dfsg-6 [195 kB] 取得:74 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-features2d3.2 armhf 3.2.0+dfsg-6 [188 kB] 取得:75 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-calib3d3.2 armhf 3.2.0+dfsg-6 [385 kB] 取得:76 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-objdetect3.2 armhf 3.2.0+dfsg-6 [131 kB] 取得:77 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-photo3.2 armhf 3.2.0+dfsg-6 [168 kB] 取得:78 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-video3.2 armhf 3.2.0+dfsg-6 [115 kB] 取得:79 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-shape3.2 armhf 3.2.0+dfsg-6 [59.8 kB] 取得:80 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-stitching3.2 armhf 3.2.0+dfsg-6 [152 kB] 取得:81 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-superres3.2 armhf 3.2.0+dfsg-6 [49.1 kB] 取得:82 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-videostab3.2 armhf 3.2.0+dfsg-6 [93.1 kB] 取得:83 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libvtk6.3 armhf 6.3.0+dfsg2-2+b6 [27.4 MB] 取得:84 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-viz3.2 armhf 3.2.0+dfsg-6 [107 kB] 取得:85 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libtesseract4 armhf 4.0.0-2 [1,032 kB] 取得:86 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopencv-contrib3.2 armhf 3.2.0+dfsg-6 [1,222 kB] 取得:87 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf libopenmpi-dev armhf 3.1.3-11+rpi1 [964 kB] 取得:88 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf proj-bin armhf 5.2.0-1 [98.2 kB] 取得:89 http://ftp.jaist.ac.jp/pub/Linux/raspbian-archive/raspbian buster/main armhf python-opencv armhf 3.2.0+dfsg-6 [487 kB] 69.6 MB を 54秒 で取得しました (1,285 kB/s) パッケージからテンプレートを展開しています: 100% 以前に未選択のパッケージ gdal-data を選択しています。 (データベースを読み込んでいます ... 現在 151245 個のファイルとディレクトリがインストールされています。) .../00-gdal-data_2.4.0+dfsg-1_all.deb を展開する準備をしています ... gdal-data (2.4.0+dfsg-1) を展開しています... 以前に未選択のパッケージ libgfortran-8-dev:armhf を選択しています。 .../01-libgfortran-8-dev_8.3.0-6+rpi1_armhf.deb を展開する準備をしています ... libgfortran-8-dev:armhf (8.3.0-6+rpi1) を展開しています... 以前に未選択のパッケージ gfortran-8 を選択しています。 .../02-gfortran-8_8.3.0-6+rpi1_armhf.deb を展開する準備をしています ... gfortran-8 (8.3.0-6+rpi1) を展開しています... 以前に未選択のパッケージ gfortran を選択しています。 .../03-gfortran_4%3a8.3.0-1+rpi2_armhf.deb を展開する準備をしています ... gfortran (4:8.3.0-1+rpi2) を展開しています... 以前に未選択のパッケージ libaec0:armhf を選択しています。 .../04-libaec0_1.0.2-1_armhf.deb を展開する準備をしています ... libaec0:armhf (1.0.2-1) を展開しています... 以前に未選択のパッケージ libarpack2:armhf を選択しています。 .../05-libarpack2_3.7.0-2_armhf.deb を展開する準備をしています ... libarpack2:armhf (3.7.0-2) を展開しています... 以前に未選択のパッケージ libsuperlu5:armhf を選択しています。 .../06-libsuperlu5_5.2.1+dfsg1-4_armhf.deb を展開する準備をしています ... libsuperlu5:armhf (5.2.1+dfsg1-4) を展開しています... 以前に未選択のパッケージ libarmadillo9 を選択しています。 .../07-libarmadillo9_1%3a9.200.7+dfsg-1_armhf.deb を展開する準備をしています ... libarmadillo9 (1:9.200.7+dfsg-1) を展開しています... 以前に未選択のパッケージ libevent-core-2.1-6:armhf を選択しています。 .../08-libevent-core-2.1-6_2.1.8-stable-4_armhf.deb を展開する準備をしています ... libevent-core-2.1-6:armhf (2.1.8-stable-4) を展開しています... 以前に未選択のパッケージ libevent-pthreads-2.1-6:armhf を選択しています。 .../09-libevent-pthreads-2.1-6_2.1.8-stable-4_armhf.deb を展開する準備をしています ... libevent-pthreads-2.1-6:armhf (2.1.8-stable-4) を展開しています... 以前に未選択のパッケージ libhwloc5:armhf を選択しています。 .../10-libhwloc5_1.11.12-3+rpi1_armhf.deb を展開する準備をしています ... libhwloc5:armhf (1.11.12-3+rpi1) を展開しています... 以前に未選択のパッケージ ocl-icd-libopencl1:armhf を選択しています。 .../11-ocl-icd-libopencl1_2.2.12-2_armhf.deb を展開する準備をしています ... ocl-icd-libopencl1:armhf (2.2.12-2) を展開しています... 以前に未選択のパッケージ libhwloc-plugins:armhf を選択しています。 .../12-libhwloc-plugins_1.11.12-3+rpi1_armhf.deb を展開する準備をしています ... libhwloc-plugins:armhf (1.11.12-3+rpi1) を展開しています... 以前に未選択のパッケージ libpmix2:armhf を選択しています。 .../13-libpmix2_3.1.2-3_armhf.deb を展開する準備をしています ... libpmix2:armhf (3.1.2-3) を展開しています... 以前に未選択のパッケージ libopenmpi3:armhf を選択しています。 .../14-libopenmpi3_3.1.3-11+rpi1_armhf.deb を展開する準備をしています ... libopenmpi3:armhf (3.1.3-11+rpi1) を展開しています... 以前に未選択のパッケージ libcaf-openmpi-3:armhf を選択しています。 .../15-libcaf-openmpi-3_2.4.0-2_armhf.deb を展開する準備をしています ... libcaf-openmpi-3:armhf (2.4.0-2) を展開しています... 以前に未選択のパッケージ libcharls2:armhf を選択しています。 .../16-libcharls2_2.0.0+dfsg-1_armhf.deb を展開する準備をしています ... libcharls2:armhf (2.0.0+dfsg-1) を展開しています... 以前に未選択のパッケージ libcoarrays-dev:armhf を選択しています。 .../17-libcoarrays-dev_2.4.0-2_armhf.deb を展開する準備をしています ... libcoarrays-dev:armhf (2.4.0-2) を展開しています... 以前に未選択のパッケージ openmpi-common を選択しています。 .../18-openmpi-common_3.1.3-11+rpi1_all.deb を展開する準備をしています ... openmpi-common (3.1.3-11+rpi1) を展開しています... 以前に未選択のパッケージ openmpi-bin を選択しています。 .../19-openmpi-bin_3.1.3-11+rpi1_armhf.deb を展開する準備をしています ... openmpi-bin (3.1.3-11+rpi1) を展開しています... 以前に未選択のパッケージ libcoarrays-openmpi-dev:armhf を選択しています。 .../20-libcoarrays-openmpi-dev_2.4.0-2_armhf.deb を展開する準備をしています ... libcoarrays-openmpi-dev:armhf (2.4.0-2) を展開しています... 以前に未選択のパッケージ libdap25:armhf を選択しています。 .../21-libdap25_3.20.3-1_armhf.deb を展開する準備をしています ... libdap25:armhf (3.20.3-1) を展開しています... 以前に未選択のパッケージ libdapclient6v5:armhf を選択しています。 .../22-libdapclient6v5_3.20.3-1_armhf.deb を展開する準備をしています ... libdapclient6v5:armhf (3.20.3-1) を展開しています... 以前に未選択のパッケージ libdapserver7v5:armhf を選択しています。 .../23-libdapserver7v5_3.20.3-1_armhf.deb を展開する準備をしています ... libdapserver7v5:armhf (3.20.3-1) を展開しています... 以前に未選択のパッケージ libepsilon1:armhf を選択しています。 .../24-libepsilon1_0.9.2+dfsg-4_armhf.deb を展開する準備をしています ... libepsilon1:armhf (0.9.2+dfsg-4) を展開しています... 以前に未選択のパッケージ libfreexl1:armhf を選択しています。 .../25-libfreexl1_1.0.5-3_armhf.deb を展開する準備をしています ... libfreexl1:armhf (1.0.5-3) を展開しています... 以前に未選択のパッケージ libfyba0:armhf を選択しています。 .../26-libfyba0_4.1.1-6_armhf.deb を展開する準備をしています ... libfyba0:armhf (4.1.1-6) を展開しています... 以前に未選択のパッケージ libgeos-3.7.1:armhf を選択しています。 .../27-libgeos-3.7.1_3.7.1-1_armhf.deb を展開する準備をしています ... libgeos-3.7.1:armhf (3.7.1-1) を展開しています... 以前に未選択のパッケージ libgeos-c1v5:armhf を選択しています。 .../28-libgeos-c1v5_3.7.1-1_armhf.deb を展開する準備をしています ... libgeos-c1v5:armhf (3.7.1-1) を展開しています... 以前に未選択のパッケージ proj-data を選択しています。 .../29-proj-data_5.2.0-1_all.deb を展開する準備をしています ... proj-data (5.2.0-1) を展開しています... 以前に未選択のパッケージ libproj13:armhf を選択しています。 .../30-libproj13_5.2.0-1_armhf.deb を展開する準備をしています ... libproj13:armhf (5.2.0-1) を展開しています... 以前に未選択のパッケージ libgeotiff2:armhf を選択しています。 .../31-libgeotiff2_1.4.3-1_armhf.deb を展開する準備をしています ... libgeotiff2:armhf (1.4.3-1) を展開しています... 以前に未選択のパッケージ libhdf4-0-alt を選択しています。 .../32-libhdf4-0-alt_4.2.13-4+b1_armhf.deb を展開する準備をしています ... libhdf4-0-alt (4.2.13-4+b1) を展開しています... 以前に未選択のパッケージ libsz2:armhf を選択しています。 .../33-libsz2_1.0.2-1_armhf.deb を展開する準備をしています ... libsz2:armhf (1.0.2-1) を展開しています... 以前に未選択のパッケージ libhdf5-103:armhf を選択しています。 .../34-libhdf5-103_1.10.4+repack-10_armhf.deb を展開する準備をしています ... libhdf5-103:armhf (1.10.4+repack-10) を展開しています... 以前に未選択のパッケージ libminizip1:armhf を選択しています。 .../35-libminizip1_1.1-8_armhf.deb を展開する準備をしています ... libminizip1:armhf (1.1-8) を展開しています... 以前に未選択のパッケージ liburiparser1:armhf を選択しています。 .../36-liburiparser1_0.9.1-1_armhf.deb を展開する準備をしています ... liburiparser1:armhf (0.9.1-1) を展開しています... 以前に未選択のパッケージ libkmlbase1:armhf を選択しています。 .../37-libkmlbase1_1.3.0-7_armhf.deb を展開する準備をしています ... libkmlbase1:armhf (1.3.0-7) を展開しています... 以前に未選択のパッケージ libkmldom1:armhf を選択しています。 .../38-libkmldom1_1.3.0-7_armhf.deb を展開する準備をしています ... libkmldom1:armhf (1.3.0-7) を展開しています... 以前に未選択のパッケージ libkmlengine1:armhf を選択しています。 .../39-libkmlengine1_1.3.0-7_armhf.deb を展開する準備をしています ... libkmlengine1:armhf (1.3.0-7) を展開しています... 以前に未選択のパッケージ libkmlconvenience1:armhf を選択しています。 .../40-libkmlconvenience1_1.3.0-7_armhf.deb を展開する準備をしています ... libkmlconvenience1:armhf (1.3.0-7) を展開しています... 以前に未選択のパッケージ libkmlregionator1:armhf を選択しています。 .../41-libkmlregionator1_1.3.0-7_armhf.deb を展開する準備をしています ... libkmlregionator1:armhf (1.3.0-7) を展開しています... 以前に未選択のパッケージ libkmlxsd1:armhf を選択しています。 .../42-libkmlxsd1_1.3.0-7_armhf.deb を展開する準備をしています ... libkmlxsd1:armhf (1.3.0-7) を展開しています... 以前に未選択のパッケージ mysql-common を選択しています。 .../43-mysql-common_5.8+1.0.5_all.deb を展開する準備をしています ... mysql-common (5.8+1.0.5) を展開しています... 以前に未選択のパッケージ mariadb-common を選択しています。 .../44-mariadb-common_1%3a10.3.15-1_all.deb を展開する準備をしています ... mariadb-common (1:10.3.15-1) を展開しています... 以前に未選択のパッケージ libmariadb3:armhf を選択しています。 .../45-libmariadb3_1%3a10.3.15-1_armhf.deb を展開する準備をしています ... libmariadb3:armhf (1:10.3.15-1) を展開しています... 以前に未選択のパッケージ libnetcdf13:armhf を選択しています。 .../46-libnetcdf13_1%3a4.6.2-1+b1_armhf.deb を展開する準備をしています ... libnetcdf13:armhf (1:4.6.2-1+b1) を展開しています... 以前に未選択のパッケージ libodbc1:armhf を選択しています。 .../47-libodbc1_2.3.6-0.1_armhf.deb を展開する準備をしています ... libodbc1:armhf (2.3.6-0.1) を展開しています... 以前に未選択のパッケージ libogdi3.2 を選択しています。 .../48-libogdi3.2_3.2.1+ds-4_armhf.deb を展開する準備をしています ... libogdi3.2 (3.2.1+ds-4) を展開しています... 以前に未選択のパッケージ libqhull7:armhf を選択しています。 .../49-libqhull7_2015.2-4_armhf.deb を展開する準備をしています ... libqhull7:armhf (2015.2-4) を展開しています... 以前に未選択のパッケージ libspatialite7:armhf を選択しています。 .../50-libspatialite7_4.3.0a-5+b2_armhf.deb を展開する準備をしています ... libspatialite7:armhf (4.3.0a-5+b2) を展開しています... 以前に未選択のパッケージ libxerces-c3.2:armhf を選択しています。 .../51-libxerces-c3.2_3.2.2+debian-1+b1_armhf.deb を展開する準備をしています ... libxerces-c3.2:armhf (3.2.2+debian-1+b1) を展開しています... 以前に未選択のパッケージ odbcinst を選択しています。 .../52-odbcinst_2.3.6-0.1_armhf.deb を展開する準備をしています ... odbcinst (2.3.6-0.1) を展開しています... 以前に未選択のパッケージ odbcinst1debian2:armhf を選択しています。 .../53-odbcinst1debian2_2.3.6-0.1_armhf.deb を展開する準備をしています ... odbcinst1debian2:armhf (2.3.6-0.1) を展開しています... 以前に未選択のパッケージ libgdal20 を選択しています。 .../54-libgdal20_2.4.0+dfsg-1+b2_armhf.deb を展開する準備をしています ... libgdal20 (2.4.0+dfsg-1+b2) を展開しています... 以前に未選択のパッケージ libsocket++1:armhf を選択しています。 .../55-libsocket++1_1.12.13-10_armhf.deb を展開する準備をしています ... libsocket++1:armhf (1.12.13-10) を展開しています... 以前に未選択のパッケージ libgdcm2.8:armhf を選択しています。 .../56-libgdcm2.8_2.8.8-9_armhf.deb を展開する準備をしています ... libgdcm2.8:armhf (2.8.8-9) を展開しています... 以前に未選択のパッケージ libgl2ps1.4 を選択しています。 .../57-libgl2ps1.4_1.4.0+dfsg1-2_armhf.deb を展開する準備をしています ... libgl2ps1.4 (1.4.0+dfsg1-2) を展開しています... 以前に未選択のパッケージ libhdf5-openmpi-103:armhf を選択しています。 .../58-libhdf5-openmpi-103_1.10.4+repack-10_armhf.deb を展開する準備をしています ... libhdf5-openmpi-103:armhf (1.10.4+repack-10) を展開しています... 以前に未選択のパッケージ libhwloc-dev:armhf を選択しています。 .../59-libhwloc-dev_1.11.12-3+rpi1_armhf.deb を展開する準備をしています ... libhwloc-dev:armhf (1.11.12-3+rpi1) を展開しています... 以前に未選択のパッケージ libnl-3-dev:armhf を選択しています。 .../60-libnl-3-dev_3.4.0-1_armhf.deb を展開する準備をしています ... libnl-3-dev:armhf (3.4.0-1) を展開しています... 以前に未選択のパッケージ libnl-route-3-dev:armhf を選択しています。 .../61-libnl-route-3-dev_3.4.0-1_armhf.deb を展開する準備をしています ... libnl-route-3-dev:armhf (3.4.0-1) を展開しています... 以前に未選択のパッケージ libibverbs-dev:armhf を選択しています。 .../62-libibverbs-dev_22.1-1_armhf.deb を展開する準備をしています ... libibverbs-dev:armhf (22.1-1) を展開しています... 以前に未選択のパッケージ liblept5 を選択しています。 .../63-liblept5_1.76.0-1_armhf.deb を展開する準備をしています ... liblept5 (1.76.0-1) を展開しています... 以前に未選択のパッケージ libnetcdf-c++4 を選択しています。 .../64-libnetcdf-c++4_4.2-11_armhf.deb を展開する準備をしています ... libnetcdf-c++4 (4.2-11) を展開しています... 以前に未選択のパッケージ libtbb2:armhf を選択しています。 .../65-libtbb2_2018~U6-4_armhf.deb を展開する準備をしています ... libtbb2:armhf (2018~U6-4) を展開しています... 以前に未選択のパッケージ libopencv-core3.2:armhf を選択しています。 .../66-libopencv-core3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-core3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-flann3.2:armhf を選択しています。 .../67-libopencv-flann3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-flann3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-imgproc3.2:armhf を選択しています。 .../68-libopencv-imgproc3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-imgproc3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-imgcodecs3.2:armhf を選択しています。 .../69-libopencv-imgcodecs3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-imgcodecs3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-videoio3.2:armhf を選択しています。 .../70-libopencv-videoio3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-videoio3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-highgui3.2:armhf を選択しています。 .../71-libopencv-highgui3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-highgui3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-ml3.2:armhf を選択しています。 .../72-libopencv-ml3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-ml3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-features2d3.2:armhf を選択しています。 .../73-libopencv-features2d3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-features2d3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-calib3d3.2:armhf を選択しています。 .../74-libopencv-calib3d3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-calib3d3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-objdetect3.2:armhf を選択しています。 .../75-libopencv-objdetect3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-objdetect3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-photo3.2:armhf を選択しています。 .../76-libopencv-photo3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-photo3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-video3.2:armhf を選択しています。 .../77-libopencv-video3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-video3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-shape3.2:armhf を選択しています。 .../78-libopencv-shape3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-shape3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-stitching3.2:armhf を選択しています。 .../79-libopencv-stitching3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-stitching3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-superres3.2:armhf を選択しています。 .../80-libopencv-superres3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-superres3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopencv-videostab3.2:armhf を選択しています。 .../81-libopencv-videostab3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-videostab3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libvtk6.3 を選択しています。 .../82-libvtk6.3_6.3.0+dfsg2-2+b6_armhf.deb を展開する準備をしています ... libvtk6.3 (6.3.0+dfsg2-2+b6) を展開しています... 以前に未選択のパッケージ libopencv-viz3.2:armhf を選択しています。 .../83-libopencv-viz3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-viz3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libtesseract4:armhf を選択しています。 .../84-libtesseract4_4.0.0-2_armhf.deb を展開する準備をしています ... libtesseract4:armhf (4.0.0-2) を展開しています... 以前に未選択のパッケージ libopencv-contrib3.2:armhf を選択しています。 .../85-libopencv-contrib3.2_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... libopencv-contrib3.2:armhf (3.2.0+dfsg-6) を展開しています... 以前に未選択のパッケージ libopenmpi-dev:armhf を選択しています。 .../86-libopenmpi-dev_3.1.3-11+rpi1_armhf.deb を展開する準備をしています ... libopenmpi-dev:armhf (3.1.3-11+rpi1) を展開しています... 以前に未選択のパッケージ proj-bin を選択しています。 .../87-proj-bin_5.2.0-1_armhf.deb を展開する準備をしています ... proj-bin (5.2.0-1) を展開しています... 以前に未選択のパッケージ python-opencv を選択しています。 .../88-python-opencv_3.2.0+dfsg-6_armhf.deb を展開する準備をしています ... python-opencv (3.2.0+dfsg-6) を展開しています... libgfortran-8-dev:armhf (8.3.0-6+rpi1) を設定しています ... mysql-common (5.8+1.0.5) を設定しています ... update-alternatives: /etc/mysql/my.cnf (my.cnf) を提供するために自動モードで /etc/mysql/my.cnf.fallback を使います libxerces-c3.2:armhf (3.2.2+debian-1+b1) を設定しています ... proj-data (5.2.0-1) を設定しています ... libcharls2:armhf (2.0.0+dfsg-1) を設定しています ... libminizip1:armhf (1.1-8) を設定しています ... libhwloc5:armhf (1.11.12-3+rpi1) を設定しています ... gfortran-8 (8.3.0-6+rpi1) を設定しています ... libproj13:armhf (5.2.0-1) を設定しています ... libtbb2:armhf (2018~U6-4) を設定しています ... libarpack2:armhf (3.7.0-2) を設定しています ... libsuperlu5:armhf (5.2.1+dfsg1-4) を設定しています ... proj-bin (5.2.0-1) を設定しています ... libdap25:armhf (3.20.3-1) を設定しています ... libqhull7:armhf (2015.2-4) を設定しています ... libepsilon1:armhf (0.9.2+dfsg-4) を設定しています ... libdapserver7v5:armhf (3.20.3-1) を設定しています ... gfortran (4:8.3.0-1+rpi2) を設定しています ... update-alternatives: /usr/bin/f95 (f95) を提供するために自動モードで /usr/bin/gfortran を使います update-alternatives: /usr/bin/f77 (f77) を提供するために自動モードで /usr/bin/gfortran を使います libgeos-3.7.1:armhf (3.7.1-1) を設定しています ... libaec0:armhf (1.0.2-1) を設定しています ... gdal-data (2.4.0+dfsg-1) を設定しています ... libgl2ps1.4 (1.4.0+dfsg1-2) を設定しています ... liblept5 (1.76.0-1) を設定しています ... mariadb-common (1:10.3.15-1) を設定しています ... update-alternatives: /etc/mysql/my.cnf (my.cnf) を提供するために自動モードで /etc/mysql/mariadb.cnf を使います libgeotiff2:armhf (1.4.3-1) を設定しています ... libgeos-c1v5:armhf (3.7.1-1) を設定しています ... libmariadb3:armhf (1:10.3.15-1) を設定しています ... libsocket++1:armhf (1.12.13-10) を設定しています ... libodbc1:armhf (2.3.6-0.1) を設定しています ... libtesseract4:armhf (4.0.0-2) を設定しています ... libevent-core-2.1-6:armhf (2.1.8-stable-4) を設定しています ... libhdf4-0-alt (4.2.13-4+b1) を設定しています ... liburiparser1:armhf (0.9.1-1) を設定しています ... libnl-3-dev:armhf (3.4.0-1) を設定しています ... libfreexl1:armhf (1.0.5-3) を設定しています ... ocl-icd-libopencl1:armhf (2.2.12-2) を設定しています ... libfyba0:armhf (4.1.1-6) を設定しています ... libkmlbase1:armhf (1.3.0-7) を設定しています ... libdapclient6v5:armhf (3.20.3-1) を設定しています ... openmpi-common (3.1.3-11+rpi1) を設定しています ... libhwloc-dev:armhf (1.11.12-3+rpi1) を設定しています ... libarmadillo9 (1:9.200.7+dfsg-1) を設定しています ... libopencv-core3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-ml3.2:armhf (3.2.0+dfsg-6) を設定しています ... libsz2:armhf (1.0.2-1) を設定しています ... libkmlxsd1:armhf (1.3.0-7) を設定しています ... libopencv-imgproc3.2:armhf (3.2.0+dfsg-6) を設定しています ... libkmldom1:armhf (1.3.0-7) を設定しています ... libspatialite7:armhf (4.3.0a-5+b2) を設定しています ... libevent-pthreads-2.1-6:armhf (2.1.8-stable-4) を設定しています ... libogdi3.2 (3.2.1+ds-4) を設定しています ... libkmlengine1:armhf (1.3.0-7) を設定しています ... libopencv-photo3.2:armhf (3.2.0+dfsg-6) を設定しています ... libkmlconvenience1:armhf (1.3.0-7) を設定しています ... libcoarrays-dev:armhf (2.4.0-2) を設定しています ... libhwloc-plugins:armhf (1.11.12-3+rpi1) を設定しています ... libnl-route-3-dev:armhf (3.4.0-1) を設定しています ... libgdcm2.8:armhf (2.8.8-9) を設定しています ... libkmlregionator1:armhf (1.3.0-7) を設定しています ... libhdf5-103:armhf (1.10.4+repack-10) を設定しています ... libopencv-video3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-flann3.2:armhf (3.2.0+dfsg-6) を設定しています ... libpmix2:armhf (3.1.2-3) を設定しています ... libopenmpi3:armhf (3.1.3-11+rpi1) を設定しています ... libnetcdf13:armhf (1:4.6.2-1+b1) を設定しています ... libibverbs-dev:armhf (22.1-1) を設定しています ... libnetcdf-c++4 (4.2-11) を設定しています ... libhdf5-openmpi-103:armhf (1.10.4+repack-10) を設定しています ... libcaf-openmpi-3:armhf (2.4.0-2) を設定しています ... libopencv-shape3.2:armhf (3.2.0+dfsg-6) を設定しています ... openmpi-bin (3.1.3-11+rpi1) を設定しています ... update-alternatives: /usr/bin/mpirun (mpirun) を提供するために自動モードで /usr/bin/mpirun.openmpi を使います update-alternatives: /usr/bin/mpicc (mpi) を提供するために自動モードで /usr/bin/mpicc.openmpi を使います libcoarrays-openmpi-dev:armhf (2.4.0-2) を設定しています ... libopenmpi-dev:armhf (3.1.3-11+rpi1) を設定しています ... update-alternatives: /usr/include/arm-linux-gnueabihf/mpi (mpi-arm-linux-gnueabihf) を提供するために自動モードで /usr/lib/arm-linux-gnueabihf/openmpi/include を使います odbcinst (2.3.6-0.1) を設定しています ... odbcinst1debian2:armhf (2.3.6-0.1) を設定しています ... libgdal20 (2.4.0+dfsg-1+b2) を設定しています ... libopencv-imgcodecs3.2:armhf (3.2.0+dfsg-6) を設定しています ... libvtk6.3 (6.3.0+dfsg2-2+b6) を設定しています ... libopencv-viz3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-videoio3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-superres3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-highgui3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-features2d3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-calib3d3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-objdetect3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-stitching3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-videostab3.2:armhf (3.2.0+dfsg-6) を設定しています ... libopencv-contrib3.2:armhf (3.2.0+dfsg-6) を設定しています ... python-opencv (3.2.0+dfsg-6) を設定しています ... libc-bin (2.28-10+rpi1) のトリガを処理しています ... man-db (2.8.5-2) のトリガを処理しています ...